人工智能实训Day2:大模型对齐技术实践——SFT与DPO
前置声明:本图文存在AI修饰
这篇文章本来应该昨天发的,但光顾着跑模型跑了一整天,等反应过来已经到今天的实训了……赶紧补上 Day2 的记录。
前言
说实话,Day1光是配环境就折腾了一整天——毕竟第一次连上那台内网服务器,从 Remote-SSH 折腾到 Zed,再到装 Miniconda、配 ai_infer 环境、装 PyTorch 和 CUDA 对齐,每一步都在跟依赖问题搏斗。不过好消息是,当 nvidia-smi 终于能正常显示我那块 NVIDIA H200 NVL (Docker 分配约 23GB) 的时候,心里那块石头总算是落地了。关于服务器的具体配置我在 Day1 的登录欢迎信息里已经贴过了,这里就不重复了。
今天我们进入正题——大模型对齐(Alignment)。如果说Day1是在"磨刀",那Day2就是真正开始"砍柴"了。

具体来说,我们要完成两个核心实验:
- SFT(Supervised Fine-Tuning,监督微调):用 GSM8K 数学数据集教会 Qwen1.5-0.5B-Chat 做数学题
- DPO(Direct Preference Optimization,直接偏好优化):用偏好数据进一步优化模型的回答质量
框架用的是 LLaMA-Factory,这个框架对大模型微调做了很好的封装,基本上只需要写好 YAML 配置文件就能一键训练。对于刚入门的人来说非常友好。
好了,话不多说,开始今天的记录。
Problem (sft1): 为什么需要大模型对齐?
在开始动手之前,我们先来理解一下:为什么需要对齐?直接拿预训练模型来用不行吗?
(a) 提示工程的局限性
很多人第一次接触大模型的时候,会觉得"写好 prompt 就够了"。确实,对于一些简单的任务,精心设计的 prompt 加上 few-shot 示例,往往能得到还不错的结果。但提示工程有几个本质上的局限:
- 天花板低:模型的知识来自预训练,prompt 只是激活已有知识,无法教给模型全新的推理模式
- 不稳定:同样的 prompt,换个问法效果可能差很多
- 无法纠正错误:如果模型在预训练中学到了错误的模式,prompt 很难彻底纠正
以我们用的 Qwen1.5-0.5B-Chat 为例——0.5B 参数的规模,说实话在预训练阶段学到的推理能力相当有限。如果直接拿来做 GSM8K 的数学题,基本就是"瞎蒙"。
(b) SFT和DPO在大模型训练中的位置
大模型的训练通常分为几个阶段:
| 阶段 | 名称 | 目标 | 典型数据 |
|---|---|---|---|
| Stage 1 | Pre-training(预训练) | 学习语言知识和世界知识 | 海量无标注文本 |
| Stage 2 | SFT(监督微调) | 学习指令遵循和对话格式 | 高质量的指令-回答对 |
| Stage 3 | RLHF/DPO(对齐) | 对齐人类偏好(有用、安全、诚实) | 偏好对比数据 |
SFT 的作用是让模型学会"如何正确地回答问题"——包括格式、风格、和基本的推理步骤。
DPO 的作用是让模型学会"什么样的回答更好"——通过对比"好的回答"和"差的回答",让模型更偏好高质量的输出。
不过有个重要的点要说明:我们今天的实验对象是 0.5B 参数 的模型。这个规模说实话非常小了(对比现在动辄几十上百B的模型),所以别对最终效果抱太高的期望。今天的目的更多是理解 SFT 和 DPO 的流程和原理,而不是训练出一个数学竞赛选手。
Problem (sft2): 环境准备与数据集
(a) 创建conda环境和安装LLaMA-Factory
Day1 的 ai_infer 环境主要是为基本推理准备的,Day2 要跑 LLaMA-Factory 做微调,我另建了一个专门的环境。下面是我用到的命令:
# 创建新的环境用于 LLM 微调(与 Day1 的 ai_infer 分开)conda create -n llm_train python=3.10conda activate llm_train
# 安装 PyTorch(与 CUDA 版本对齐)pip install torch
# 克隆LLaMA-Factory仓库git clone https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factory
# 安装依赖pip install -e ".[torch,metrics]"
# 验证安装llamafactory-cli version
安装完成后,先检查一下 CUDA 是否正常工作:
python -c "import torch; print(f'PyTorch: {torch.__version__}'); print(f'CUDA: {torch.version.cuda}'); print(f'GPU: {torch.cuda.get_device_name(0)}')"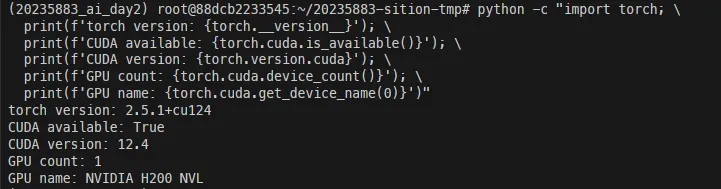
不出意外的,H200 NVL(Docker 分配约 23GB,之前 Day1 登录时也看到了)顺利识别,CUDA 环境一切正常。23GB 对于 0.5B 参数的模型来说是绰绰有余的,甚至可以考虑全量微调(Full Fine-tuning)而不是 LoRA。
(b) GSM8K和Math-Step-DPO-10K数据集介绍
今天用到两个数据集:
GSM8K(Grade School Math 8K)是 OpenAI 发布的小学数学应用题数据集。它包含 7,473 道训练题 和 1,319 道测试题。每道题都需要多步推理才能得出正确答案,是测试大模型数学推理能力的经典 benchmark。
一个典型的 GSM8K 样本长这样:
Question: James decides to run 3 sprints 3 times a week. He runs 60 meters each sprint. How many total meters does he run a week?Answer: 540注意这里的 answer 只有最终答案(540),没有中间推理过程。这也是为什么 GSM8K 的评测指标通常用 Exact Match——只看模型输出的最后数字是否和答案一致。
Math-Step-DPO-10K 是一个偏好数据集,约 10,795 条数据。它的格式和 GSM8K 不同,每条数据包含:
question:数学题目chosen:人类偏好的、正确的、带详细推理步骤的回答rejected:相对较差或错误的回答
这种 chosen vs rejected 的成对结构正是 DPO 训练所需要的。


Problem (sft3): SFT监督微调实验
(a) 数据准备和配置
LLaMA-Factory 的训练配置全部写在 YAML 文件里。对于 SFT,我的配置文件大致如下:
model_name_or_path: Qwen/Qwen1.5-0.5B-Chattemplate: qwendataset: gsm8k_traincutoff_len: 1024max_samples: 100000overwrite_cache: truepreprocessing_num_workers: 16
# 训练配置output_dir: saves/qwen1.5-0.5b/sftper_device_train_batch_size: 4gradient_accumulation_steps: 4num_train_epochs: 3.0learning_rate: 1.0e-4lr_scheduler_type: cosinewarmup_ratio: 0.1bf16: trueddp_timeout: 180000
# 评估val_size: 0.1per_device_eval_batch_size: 4eval_strategy: stepseval_steps: 100
# 日志logging_steps: 10save_steps: 500plot_loss: true这里有几个关键配置说明一下:
template: qwen:指定使用 Qwen 模型的对话模板,确保输入格式和预训练时一致cutoff_len: 1024:最大序列长度,数学题一般不需要太长bf16: true:使用 bfloat16 混合精度训练,节省显存的同时保持较好的数值稳定性num_train_epochs: 3:训练 3 轮,经验上对于小数据集足够了
(b) 训练启动和过程
配置好后,一条命令就能启动训练:
llamafactory-cli train sft_config.yaml
训练开始后,终端会实时输出 loss 和 learning rate 的变化。说实话,看着 loss 从 0.8 左右一路往下掉,还是挺有成就感的。
整个 SFT 训练持续了 约 1 小时 16 分钟。对于 7473 条训练数据跑 3 个 epoch 来说,这个时间还是合理的。毕竟虽然是 0.5B 的小模型,但数学推理的数据序列普遍比较长,计算量不算小。
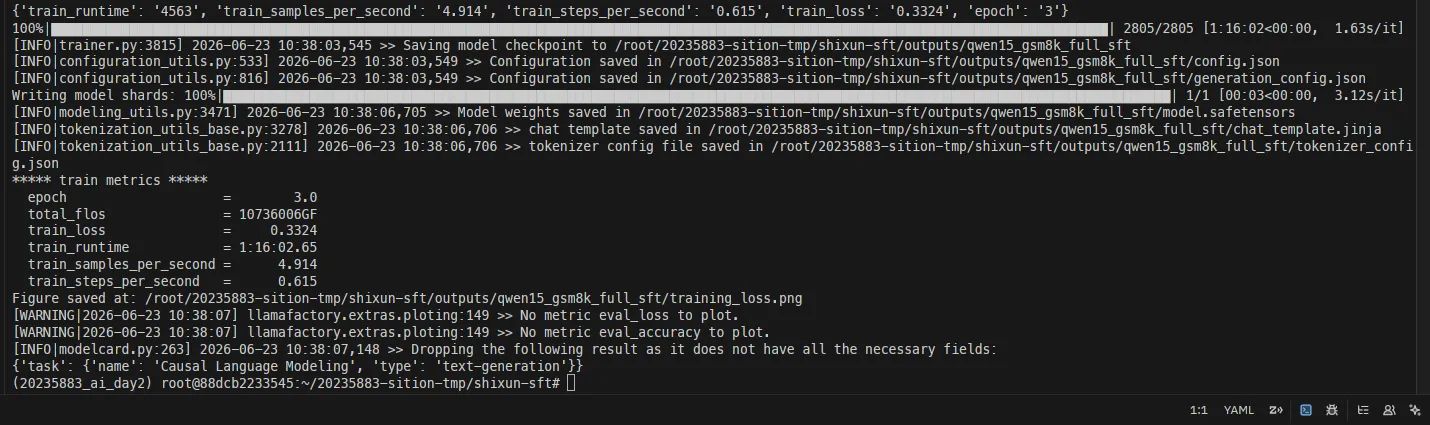
(c) 训练可视化
LLaMA-Factory 会自动生成 loss 曲线图。从曲线上可以清楚地看到训练过程的变化:
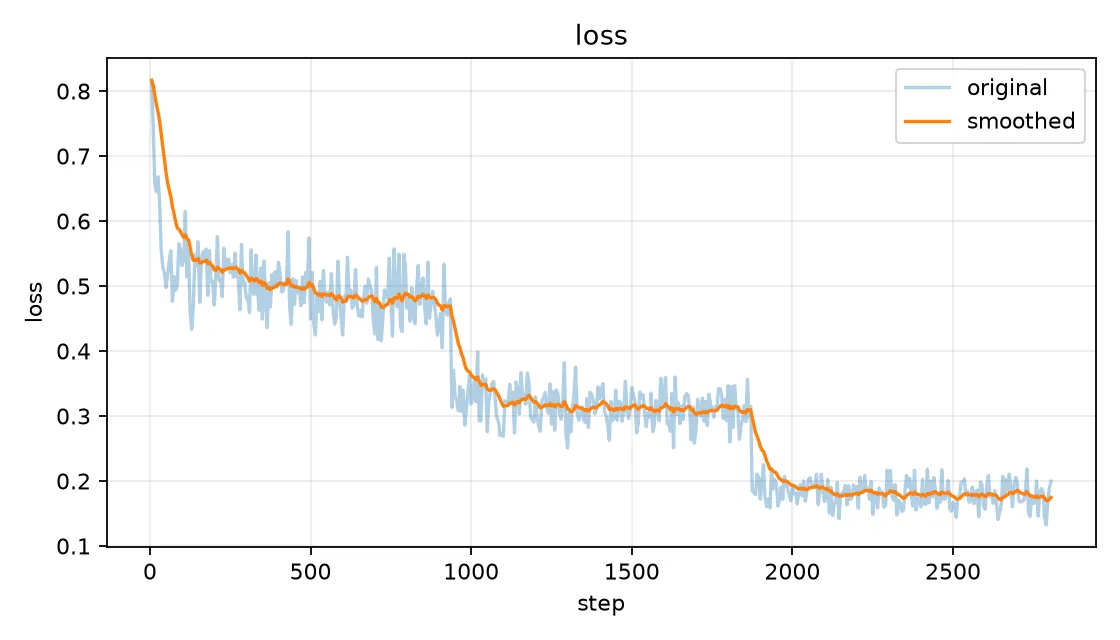
- 初始 loss:约 0.82
- 最终 loss:约 0.18
- 下降趋势:比较平滑,没有明显的震荡或过拟合迹象
这个 loss 的下降说明模型确实在学习——它在逐渐适应 GSM8K 数据的分布,学会了按我们期望的格式输出数学推理过程。
(d) Exact Match评测
SFT 训练完成后,我们用 GSM8K 的测试集来评测。评测方式是 Exact Match:从模型输出中提取最后一个数字,和正确答案比对。
llamafactory-cli eval eval_config.yaml评测结果:
| 指标 | 数值 |
|---|---|
| 测试集大小 | 1,319 题 |
| 正确题数 | 310 题 |
| Exact Match 准确率 | 23.5% |
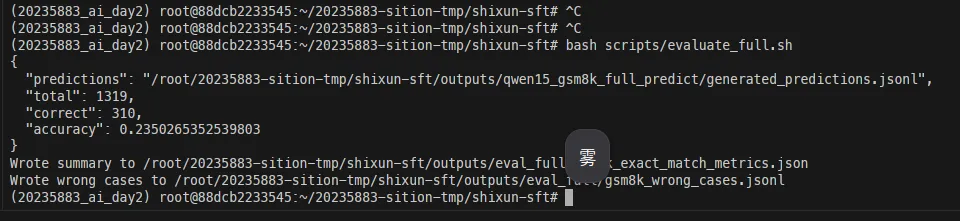
23.5% 的准确率,说实话不高,但对于 0.5B 参数的模型来说也并非完全不可接受。要知道,Qwen1.5-0.5B-Chat 在未经 SFT 的情况下做 GSM8K,准确率可能连 5% 都不到。经过 SFT 后从"几乎不会"提升到"每四题对一题",已经算是有意义的进步了。
这里也要理解 Exact Match 的严格性:只要最后提取的数字有一点偏差(比如多算或少算一位),就算全错。它衡量的其实是"完全正确的推理",而不是"部分正确的推理"。
Problem (sft4): DPO直接偏好优化实验
(a) DPO原理简介
DPO(Direct Preference Optimization)是 2023 年提出的一种大模型对齐方法。它来源于 RLHF(Reinforcement Learning from Human Feedback),但比 RLHF 更简单直接。
传统 RLHF 的流程是:
- 训练一个 Reward Model(奖励模型)来学习人类偏好
- 用 PPO(Proximal Policy Optimization)等强化学习算法优化策略
这个流程非常重——需要维护多个模型,训练过程也不稳定。
DPO 的核心洞察是:其实不需要显式地训练 Reward Model,也不需要强化学习。DPO 直接从偏好数据(chosen/rejected 对)出发,用一个简单的损失函数就能达到类似的效果。
具体来说,对于每条偏好数据,DPO 的损失函数是:
其中:
- 是问题(question)
- 是 chosen(更好的回答)
- 是 rejected(更差的回答)
- 是当前策略(正在训练的模型)
- 是参考策略(通常是 SFT 后的模型,固定不更新)
- 是温度系数,控制优化强度
用人话翻译一下:DPO 做的事情就是,让模型在 chosen 回答上的概率尽量高,在 rejected 回答上的概率尽量低。中间的 参数控制这个"偏好"的强度。
Reward Margin 是 DPO 训练中的一个关键监控指标,它表示模型对 chosen 和 rejected 的"区分能力"。理想情况下,这个值应该逐渐增大,说明模型越来越能分辨好坏回答。
(b) 数据准备和训练
DPO 训练使用的是 Math-Step-DPO-10K 数据集,每条数据都包含 question、chosen 和 rejected 三个字段。
model_name_or_path: saves/qwen1.5-0.5b/sft # 基于SFT后的模型template: qwendataset: math_step_dpo_10kcutoff_len: 1024
# DPO特有配置pref_beta: 0.1pref_loss: dpo
# 训练配置output_dir: saves/qwen1.5-0.5b/dpoper_device_train_batch_size: 2gradient_accumulation_steps: 8num_train_epochs: 3.0learning_rate: 5.0e-5lr_scheduler_type: cosinewarmup_ratio: 0.1bf16: true注意这里 model_name_or_path 指向的是 SFT 训练后的模型目录,而不是原始预训练模型。这是 DPO 的标准做法——在 SFT 的基础上进一步优化。
pref_beta: 0.1 是 DPO 的关键超参数,后面进阶任务中我们会详细分析它的影响。
llamafactory-cli train dpo_config.yamlDPO 训练比 SFT 慢不少,最终耗时 约 4 小时 8 分钟。原因主要是 DPO 每轮训练需要分别对 chosen 和 rejected 做两次前向传播,计算量更大。
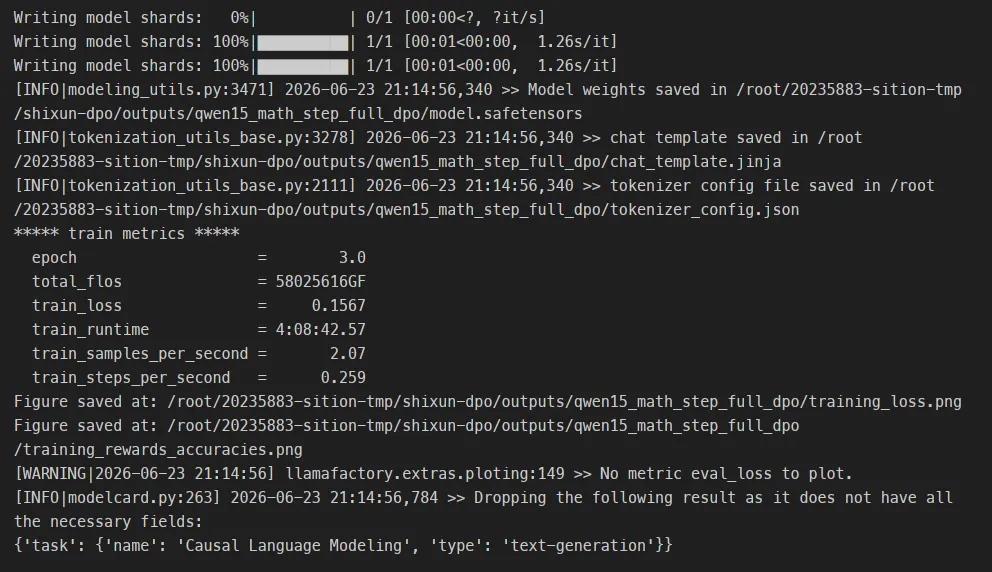
最终训练 loss 降到了 0.1567,整个训练过程比较稳定。
(c) 训练可视化
先来看 loss 曲线:
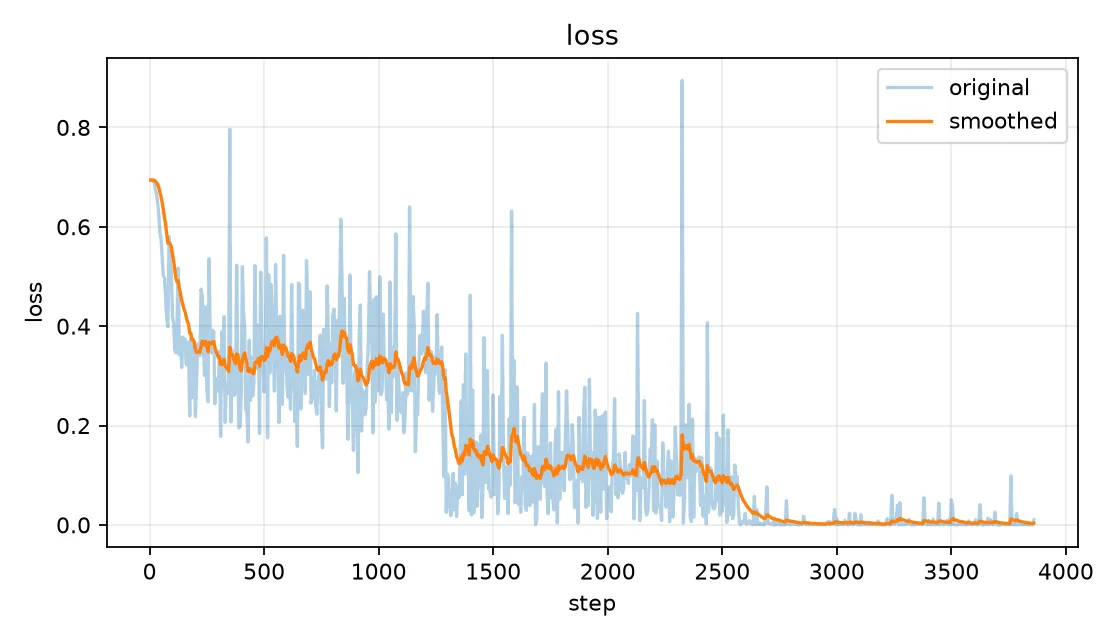
然后是 DPO 特有的 Reward Margins 曲线:
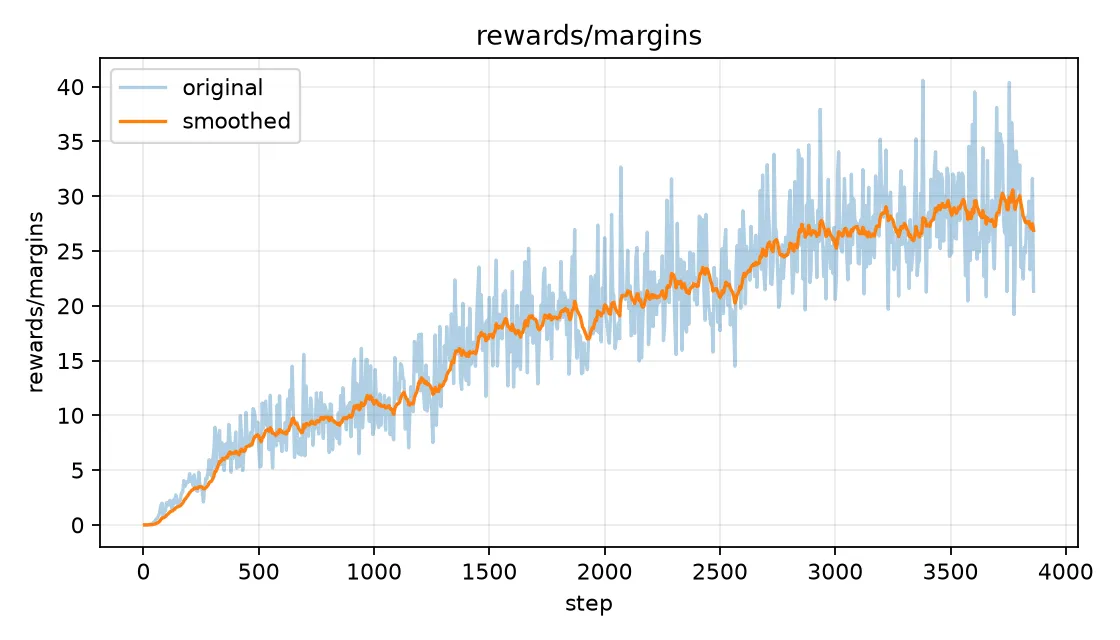
这个 Reward Margins 图非常有信息量。可以看到:
- 初始阶段:Reward Margin 接近 0,说明刚开始模型对 chosen 和 rejected 的区分能力很弱
- 训练过程:Margin 逐渐扩大,从 0 一路增长到 约 30
- 最终状态:模型已经能很好地区分 chosen 和 rejected 了
这说明 DPO 训练是成功的——模型学会了"什么样的回答更好"。
(d) SFT vs DPO对比分析
这是很多人关心的部分:DPO 之后的模型,真的比 SFT 好吗?
我们用相同的 100 道测试题分别评测了 SFT 模型和 DPO 模型:
| 模型 | 测试题数 | 正确题数 | 准确率 |
|---|---|---|---|
| SFT | 100 | 4 | 4% |
| DPO | 100 | 1 | 1% |
嗯……看到这个结果的时候,说实话我也愣了一下。DPO 的 Exact Match 准确率反而比 SFT 低了?
但仔细想想,这其实是一个很关键的认知:DPO 的目标不是提升 Exact Match 准确率,而是优化偏好排序。DPO 让模型更喜欢"好的回答",但"好的回答"和"正确答案"不完全是一回事。
具体来说:
- DPO 的优化目标 是让模型输出更"像" chosen(更详细、更有条理、更符合人类偏好)的回答,而不是让最终数字更正确
- 0.5B 模型的表达能力有限,DPO 在优化偏好表达的同时,可能会牺牲一定的精确计算能力
- Exact Match 是一个严格的指标,DPO 模型可能在推理步骤上更合理,但最后一步算错了,依然得 0 分
这个对比其实给了我们一个很重要的教训:评价一个模型要看你用的是什么指标。如果用 Reward Accuracy(模型对 chosen 的偏好是否正确),DPO 模型肯定比 SFT 好得多;但如果用 Exact Match,结果可能就没那么漂亮了。
Problem (advanced1): CoT推理时增强(进阶任务)
(a) 5种Prompt模板设计思路
做完了基础实验,接下来我们尝试一个有趣的进阶任务:推理时增强(Test-time Augmentation),具体来说就是不同的 Chain-of-Thought(CoT,思维链)Prompt 模板。
CoT 的核心思想很简单:与其让模型直接输出答案,不如让它"一步一步地想"(let's think step by step)。这种方式对于需要推理的任务非常有效。
我设计了 5 种不同的 CoT Prompt 模板,来测试哪种对小模型最有效:
1. basic(标准逐步推理)
请逐步推理并回答以下数学问题:{question}请一步一步思考,最后给出答案。这是最基础的 CoT 提示,只要求模型逐步推理。
2. key_info(先提取关键条件)
请逐步推理并回答以下数学问题:{question}请先提取问题中的关键信息,然后逐步计算,最后给出答案。这个模板增加了一个"提取关键信息"的前置步骤,模拟人解题时先分析条件的习惯。
3. intermediate_check(每步验证)
请逐步推理并回答以下数学问题:{question}请在每步计算后进行验证,确保正确后再继续,最后给出答案。这个模板要求模型在每一步计算后进行自我验证,试图减少累积错误。
4. comprehensive(综合策略)
请逐步推理并回答以下数学问题:{question}请先分析题意,提取关键条件,然后选择合适的解题策略,逐步计算并在每步验证,最后给出答案。这个模板整合了前面几种策略,是一个"大而全"的版本。
5. self_check(推理后自检)
请逐步推理并回答以下数学问题:{question}请一步一步思考。完成推理后,请检查你的答案是否合理,如果发现问题请重新计算,最后给出最终答案。这个模板在推理结束后增加了一个自检环节,让模型反思自己的答案。
(b) 实验结果与分析
我们在 100 道 GSM8K 测试题上分别测试了这 5 种模板。实验用的是 SFT-3(经过 SFT 训练的模型):
结果如下:
| 模板 | 准确率 | 描述 |
|---|---|---|
| basic | 7.00% | 标准逐步推理 |
| key_info | 7.00% | 先提取关键条件 |
| intermediate_check | 6.00% | 每步验证 |
| comprehensive | 5.00% | 综合策略 |
| self_check | 4.00% | 推理后自检 |
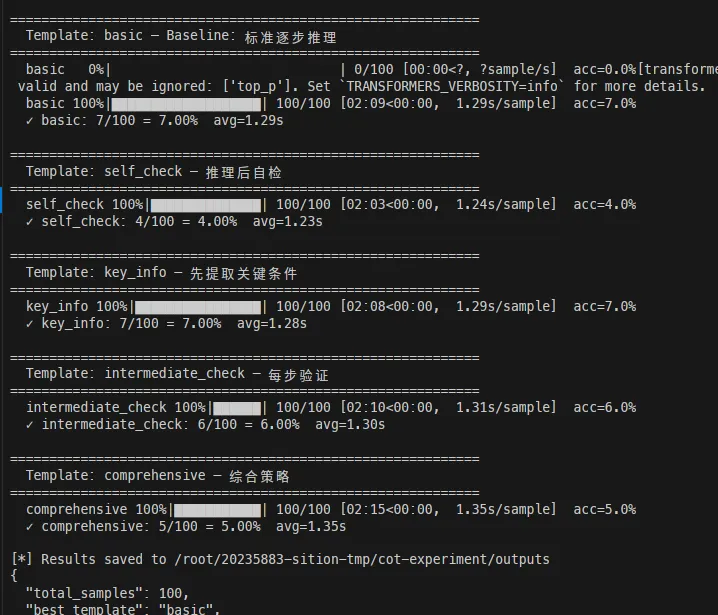
这个结果非常有意思。最简单的 basic 模板反而效果最好,而越复杂的模板效果越差。
我的分析是这样的:
- 0.5B 模型的指令理解能力有限。复杂的 prompt 包含多个要求(提取条件 + 选择策略 + 逐步计算 + 验证),小模型很难同时执行好所有这些步骤。
- 每增加一个指令,都可能引入新的错误点。比如 intermediate_check 要求"每步验证",但模型可能理解不了什么是"验证",反而把验证步骤搞成了无意义的重复,打乱了正常的推理流程。
- basic 模板只要求"一步步想",这是 CoT 最核心的要素,也是最简单、最不容易出错的指令。
这个实验给我的启发是:对于小模型来说,prompt 设计要遵循"奥卡姆剃刀"原则——能简单就别复杂。你自以为在帮模型"理清思路",实际上可能是在增加认知负担。
Problem (advanced2): β参数敏感性分析(进阶任务)
(a) β参数的作用
还记得 DPO 损失函数里的 吗?它是 DPO 中最重要的超参数之一,直接控制着优化的"激进程度":
- 越大:优化越保守,模型更靠近参考模型(SFT 模型),变化小
- 越小:优化越激进,模型可以更大幅度地偏离参考模型
的本质是控制 KL 散度的惩罚强度——它限制 DPO 模型和参考模型之间的差异,防止优化过度导致模型"跑偏"。
(b) 三种β值的对比实验
为了找到合适的 值,我跑了三组对比实验:
第一组:β = 0.05(LoRA, 1 epoch)
pref_beta: 0.05finetuning_type: loranum_train_epochs: 1.0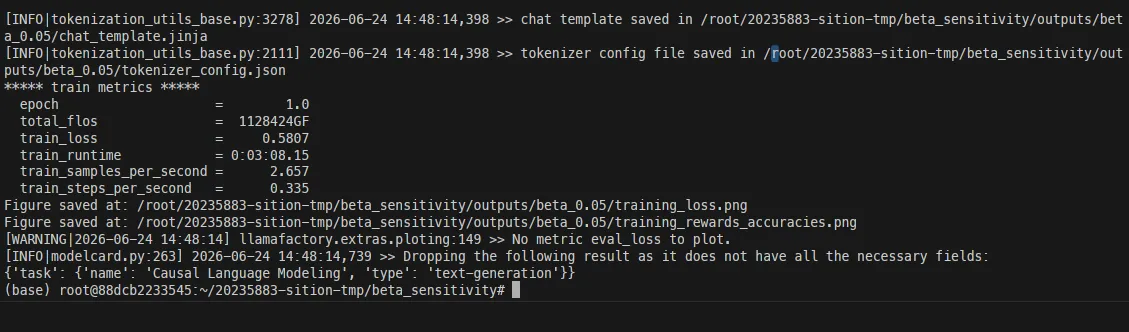
- Loss: 0.5807
- Reward Margin: ~1.17
第二组:β = 0.1(Full Fine-tuning, 3 epochs)
pref_beta: 0.1finetuning_type: fullnum_train_epochs: 3.0这是之前 SFT4 中用的配置,效果最好。
- Loss: 0.1567
- Reward Margin: ~31.6
第三组:β = 0.2(LoRA, 1 epoch)
pref_beta: 0.2finetuning_type: loranum_train_epochs: 1.0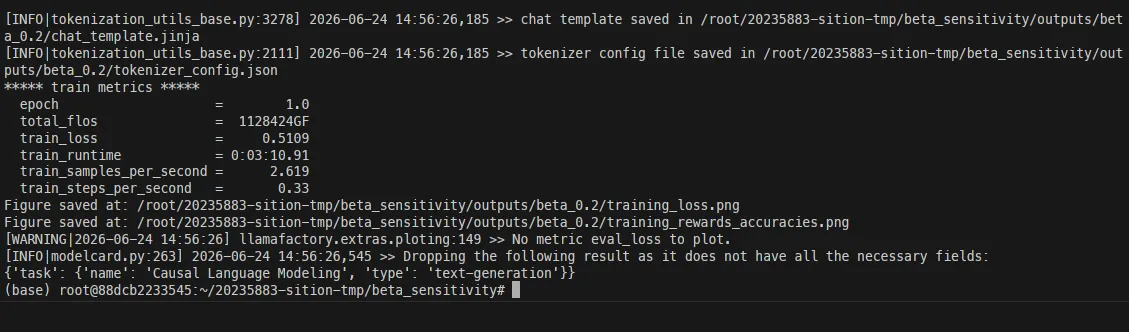
- Loss: 0.5109
- Reward Margin: ~2.11
(c) 结论与推荐
三组实验的数据汇总对比:
| β | 训练方式 | Loss | Reward Margin |
|---|---|---|---|
| 0.05 | LoRA 1ep | 0.5807 | ~1.17 |
| 0.1 | Full 3ep | 0.1567 | ~31.6 |
| 0.2 | LoRA 1ep | 0.5109 | ~2.11 |
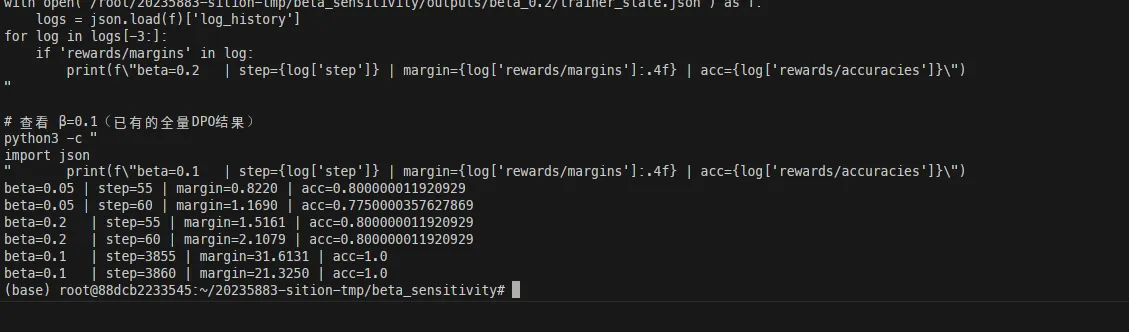
这里要说明一下——三组实验的训练配置不完全一致(Full vs LoRA,3ep vs 1ep),所以不能严格地只做 的单变量对比。但从趋势上还是可以得到一些结论:
- 时 Reward Margin 最大(~31.6),说明模型对 chosen/rejected 的区分能力最强
- 过小(0.05):优化过于激进但训练不充分,模型可能偏离参考模型太远,导致 reward margin 反而小
- 过大(0.2):KL 惩罚太强,模型被"拉"回参考模型,优化效果受限
推荐:对于类似的实验设置, 在 0.05 ~ 0.1 范围内是比较合理的选择。如果训练更充分(更多 epoch、更大 batch),可以尝试更小的 来获得更强的优化效果。
总结
到今天为止,人工智能实训第二阶段的核心任务就全部完成了。回顾一下今天的收获:
| 实验 | 核心指标 | 结果 |
|---|---|---|
| SFT(GSM8K) | Exact Match | 23.5%(310/1319) |
| DPO(Math-Step-DPO-10K) | Reward Margin | 从 0 扩大到 ~30 |
| SFT vs DPO | 100题准确率 | SFT 4% vs DPO 1% |
| CoT模板对比 | 最佳模板 | basic(7%) |
| β敏感性分析 | 最优β | 0.05 ~ 0.1 |
几个关键的 take-away:
- SFT 是有效的:0.5B 模型经过 SFT 后,GSM8K 准确率从接近 0 提升到 23.5%,证明了监督微调的价值
- DPO 的目标要明确:DPO 优化的是偏好排序,不是 Exact Match。用错误的指标评价会得到令人困惑的结论
- CoT 提示要简洁:对于小模型,简单的 prompt 往往比复杂的 prompt 更有效
- 超参数调优很重要: 的选择对 DPO 效果影响很大,需要根据实际实验来确定
说实话,今天的训练等待时间确实挺长的(SFT 1小时 + DPO 4小时),但在这个过程中我真正理解了对齐技术的来龙去脉,而不仅仅是跑通了代码。
明天见。
人工智能实训Day2:大模型对齐技术实践——SFT与DPO
作者:xingwangzhe
本文链接:https://xingwangzhe.fun/posts/ai-training-sft-dpo-day2/
本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
留言评论