人工智能实训Day1:Ubuntu 基础与 Conda 推理环境搭建
前言
不出意外的,我的实训 II 被调剂到人工智能方向了,我感觉这个还挺有意思的,先记录一下。

分配 Ubuntu 用户
老师说为了实训,好不容易申请到 H200 来用,不过分配到 70 多个人、10 多个小组,都是 Docker 分块。
____ _ _ _ ___ / ___|(_) |_ ___ _ __ / \ |_ _| \___ \| |__/ _ \| '_ \ / _ \ | | ___) | | || (_) | | | |/ ___ \ | | |____/|_|\__\___/|_| |_/_/ \_\___|
操作系统: Ubuntu 22.04.5 LTS, x86_64 处 理 器: INTEL(R) XEON(R) GOLD 6530, 5 核心 内 存: 41.0 GB 运 算 卡: NVIDIA H200 NVL, 1, 23552 MiB 存 储: 挂载点 操作权限 分区使用率 已使用/总空间 / 读写 9% 22G/258G /root/siton-pub 只读 13% 98G/816G /root/siton-data-1f55405a64d24fe2819a81c90df30517 读写 52% 67G/128G /root/siton-tmp 读写 1% 12K/256G
*温馨提示: 1.系统盘空间较小,请将较大的数据存放在网盘或者缓存盘中。 2.重置系统时缓存盘与网盘中的数据不受影响。 3.帮助文档: https://docs.aiserver.cn/SitonCloud/introduction/。 4.使用过程中如有疑问,请咨询系统管理员或联系思腾合力技术支持
Last login: Mon Jun 22 11:18:26 2026 from 127.0.0.1-bash: warning: setlocale: LC_ALL: cannot change locale (zh_CN.UTF-8)服务器不连网?
指导书上写的是用 VS Code 的 Remote-SSH 连接,而且只在大内网里才能连上,也就是服务器不能联网下载 VS Code Server,得客户端下载之后再 copy 到服务器里,才能做好完整的 VS Code Server 连接。
{ "remote.SSH.localServerDownload": "always", "remote.SSH.remotePlatform": { "ubuntu-offline": "linux", "ubuntu-lihengyu": "linux" }, "remote.SSH.showLoginTerminal": true}“remote.SSH.localServerDownload”: “always”
这项设置会让 VS Code Server 先由本机下载,再上传到离线 Ubuntu 服务器,从而避免服务器无法联网下载组件的问题。设置完成后,可以在 Remote-SSH: Connect to Host 中选择已经配置好的主机名进行连接。
但我 apt install 的时候看见了阿里云镜像,恩……也不是没联网嘛。
逐个任务
Problem (linux1): Understanding Linux and Ubuntu
(a) Linux 和 Ubuntu 是同一个东西吗?
不是 Linux 是操作系统的内核,而 Ubuntu 是基于 Linux 内核构建的一个发行版。可以把 Linux 理解为汽车发动机,Ubuntu 则是搭载这个发动机的一款整车。
(b) 为什么人工智能实训课程常使用 Ubuntu,而不是只使用 Windows?
- 深度学习环境配置:主流 AI 框架(PyTorch、TensorFlow 等)和 CUDA 驱动在 Linux/Ubuntu 上的支持更成熟,安装和版本管理更方便。
- 服务器使用:实际训练和推理通常跑在远程服务器上,Ubuntu Server 稳定、占用资源少,适合长时间运行的 GPU 任务。
- 命令行操作:Ubuntu 拥有强大的 Shell 和包管理工具(apt、Conda、pip),便于自动化脚本、环境复现和批量任务。
Problem (vscode1): Connecting to the Ubuntu server
课程要求使用 VS Code + Remote-SSH 连接服务器,但我电脑上 VS Code 有些问题,所以改用 Zed 的远程开发功能连接,本质一样:都是在本地编辑器里操作远程 Ubuntu 服务器的文件和终端。
完成步骤:
- 在本地安装 Zed(或 VS Code)。
- 配置 SSH 连接到课程提供的 Ubuntu 服务器(
202.199.13.141)。 - 在远程终端中依次运行以下命令:
whoamihostnamepwduname -a运行结果截图如下:
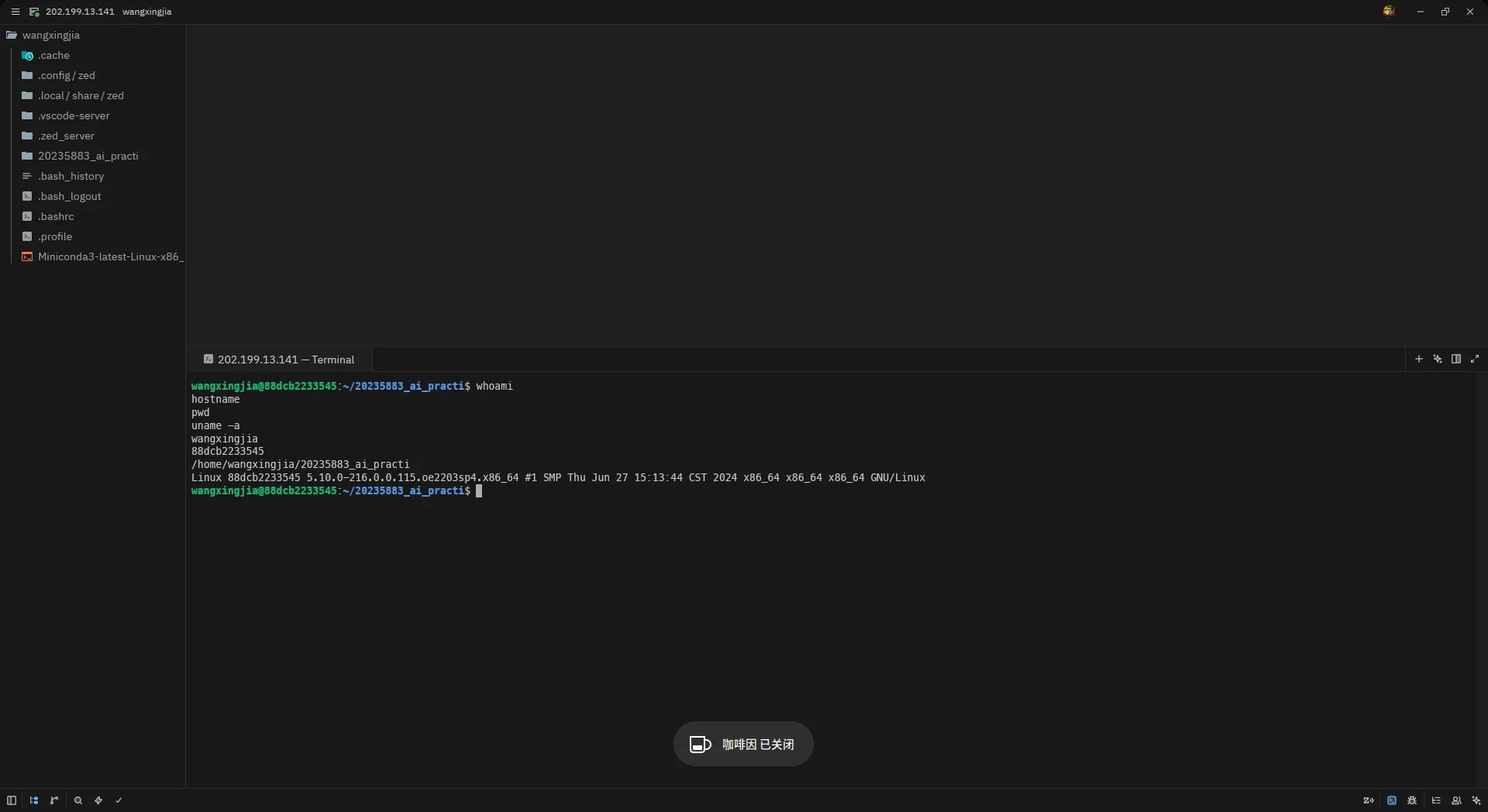
命令输出:
wangxingjia88dcb2233545/home/wangxingjia/20235883_ai_practiLinux 88dcb2233545 5.10.0-216.0.0.115.oe2203sp4.x86_64 #1 SMP Thu Jun 27 15:13:44 CST 2024 x86_64 x86_64 x86_64 GNU/Linux说明:
whoami输出当前登录用户wangxingjia。hostname输出容器/服务器主机名88dcb2233545。pwd输出当前工作目录/home/wangxingjia/20235883_ai_practi。uname -a输出系统内核信息,确认运行的是 Linux x86_64 架构。
Problem (vscode2): Local computer or remote Ubuntu?
(a) VS Code 安装在个人电脑上,为什么可以操作 Ubuntu 服务器中的文件?
因为 Remote-SSH 插件通过 SSH 协议在本地 VS Code 和远程 Ubuntu 服务器之间建立安全连接。VS Code 会把文件编辑、终端输入等操作请求发送到远程服务器上执行,再把结果返回显示在本地窗口。所以看起来像是在本地操作,实际文件和命令都在远程服务器上运行。
(b) 在远程终端中创建的文件夹,会出现在本地桌面上吗?
不会 远程终端运行在 Ubuntu 服务器上,mkdir 等命令创建的文件和目录都保存在远程服务器的文件系统中,不会同步到本地电脑的桌面上。
Problem (shell1): First command-line operations
在远程 Ubuntu 终端中完成目录创建任务,学号为 20235883,所以目录命名为 20235883_ai_practice。
使用的命令:
# 查看当前所在目录pwd
# 回到用户主目录cd ~
# 创建个人实训目录mkdir 20235883_ai_practice
# 进入该目录cd 20235883_ai_practice
# 创建三个子文件夹mkdir data src outputs
# 查看创建结果ls终端截图:
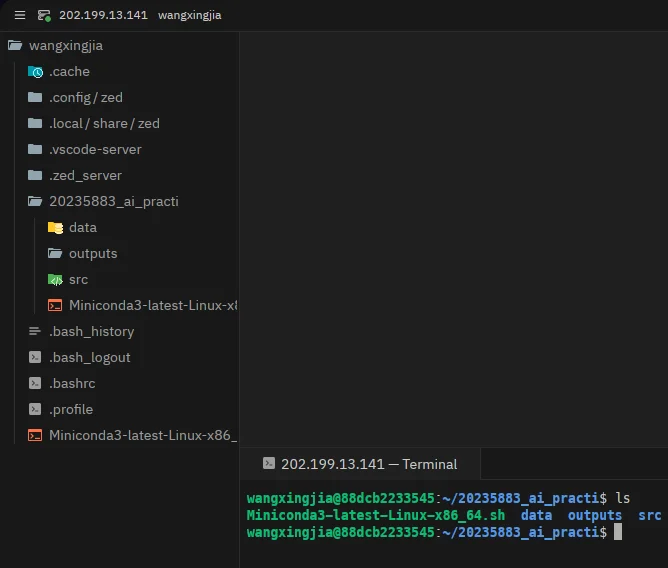
从截图可以看到,20235883_ai_practice 目录下成功创建了 data、src、outputs 三个子文件夹。左侧文件树和终端 ls 输出都验证了这一点。
Problem (file1): Managing a small project directory
在 20235883_ai_practice 目录下完成文件创建、复制、查看与删除操作。
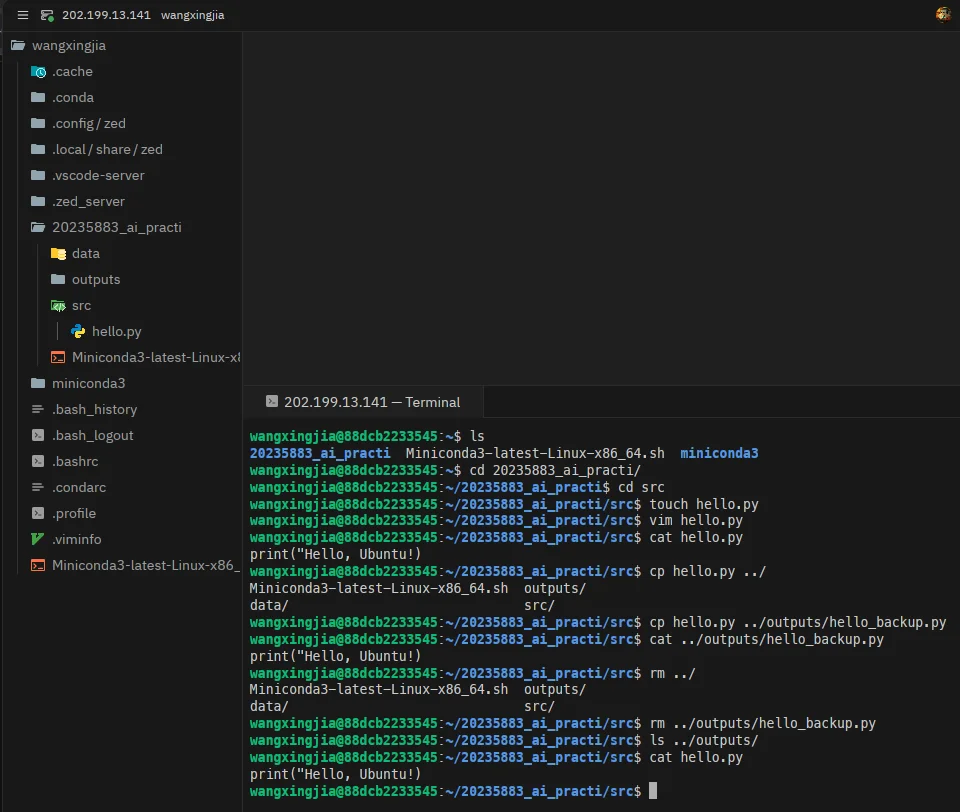
完整命令记录:
# 进入项目目录wangxingjia@88dcb2233545:~$ cd 20235883_ai_practice/
# 1. 进入 src 文件夹wangxingjia@88dcb2233545:~/20235883_ai_practice$ cd src
# 2. 创建 hello.pywangxingjia@88dcb2233545:~/20235883_ai_practice/src$ touch hello.py
# 3. 向文件中写入内容(截图中使用 vim 编辑,也可用 echo 直接写入)wangxingjia@88dcb2233545:~/20235883_ai_practice/src$ echo 'print("Hello, Ubuntu!")' > hello.py
# 查看写入结果wangxingjia@88dcb2233545:~/20235883_ai_practice/src$ cat hello.pyprint("Hello, Ubuntu!")
# 4. 返回 20235883_ai_practice 目录wangxingjia@88dcb2233545:~/20235883_ai_practice/src$ cd ..
# 5. 将 src/hello.py 复制到 outputs/hello_backup.pywangxingjia@88dcb2233545:~/20235883_ai_practice$ cp src/hello.py outputs/hello_backup.py
# 6. 查看 outputs/hello_backup.py 的内容wangxingjia@88dcb2233545:~/20235883_ai_practice$ cat outputs/hello_backup.pyprint("Hello, Ubuntu!")
# 7. 删除备份文件wangxingjia@88dcb2233545:~/20235883_ai_practice$ rm outputs/hello_backup.py
# 确认 outputs 目录已清空wangxingjia@88dcb2233545:~/20235883_ai_practice$ ls outputs/
# 原文件仍在 src 中wangxingjia@88dcb2233545:~/20235883_ai_practice$ cat src/hello.pyprint("Hello, Ubuntu!")终端截图:
cp、mv、rm 三个命令的区别
| 命令 | 全称 | 作用 | 原文件是否保留 |
|---|---|---|---|
cp |
copy | 复制文件或目录,生成一份副本 | 保留,原文件仍在原处 |
mv |
move | 移动文件或目录的位置,也可用于重命名 | 不保留,原位置文件消失 |
rm |
remove | 删除文件或目录 | 删除后不可恢复(无回收站) |
cp:常用于备份、复制文件到另一个目录,或在同一目录下生成同名/异名副本。例如cp src/hello.py outputs/hello_backup.py就是在outputs目录下生成hello.py的备份。mv:用于移动文件位置或修改文件名。例如mv src/hello.py outputs/hello.py会把原文件从src移到outputs;mv hello.py hi.py则是重命名。rm:用于清理不再需要的文件或目录,执行后文件通常直接被移除,无法通过图形界面的“回收站”找回,因此删除前务必确认路径正确,尤其是使用rm -r递归删除目录时更要谨慎。
Problem (apt1): Installing basic tools
在 Ubuntu 中更新软件源并安装 tree,然后用 tree 查看 20235883_ai_practice 的目录结构。
完整命令记录:
# 1. 更新软件源wangxingjia@88dcb2233545:~$ sudo apt update
# 2. 安装 treewangxingjia@88dcb2233545:~$ sudo apt install tree
# 3. 进入项目目录wangxingjia@88dcb2233545:~$ cd 20235883_ai_practice
# 4. 运行 tree 查看目录结构wangxingjia@88dcb2233545:~/20235883_ai_practice$ tree.├── Miniconda3-latest-Linux-x86_64.sh├── data├── outputs└── src └── hello.py
3 directories, 2 files终端截图:
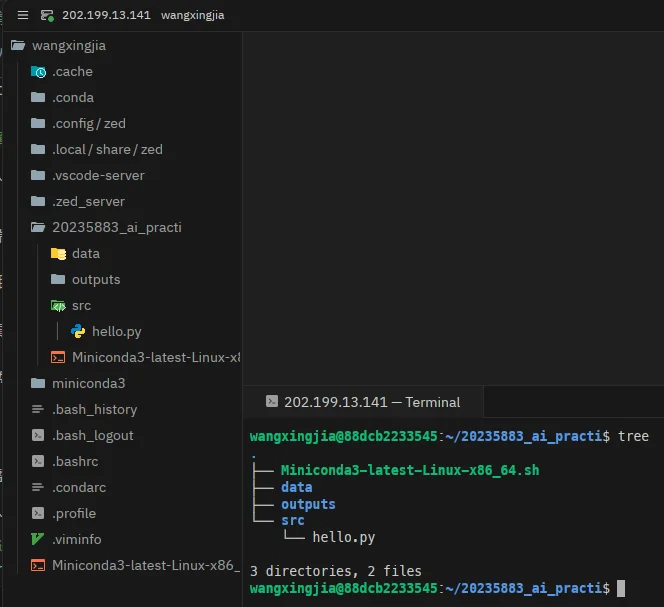
tree 输出显示 20235883_ai_practice 目录下包含 data、outputs、src 三个子目录,以及 src/hello.py 和 Miniconda3-latest-Linux-x86_64.sh 两个文件,共 3 directories, 2 files。
apt 和 pip 的区别
apt是 Ubuntu/Debian 系统级的包管理器,用于安装操作系统层面的软件和工具(如tree、git、python3),通常需要sudo权限,管理软件包及其系统依赖。pip是 Python 专用的包管理器,用于安装 Python 第三方库(如numpy、torch、requests),通常在虚拟环境或 Conda 环境中使用,管理的是 Python 项目依赖。
简单来说:apt 管系统软件,pip 管 Python 库;apt 面向整个系统,需要管理员权限,而 pip 更适合在隔离的 Python 环境中安装项目所需的库。
Problem (miniconda1): Installing Miniconda
在远程 Ubuntu 服务器中安装 Miniconda,完成初始化并检查安装结果。
完整命令记录:
# 1. 找到课程提供的 Miniconda 安装包wangxingjia@88dcb2233545:~$ ls 20235883_ai_practice/Miniconda3-latest-Linux-x86_64.sh data outputs src
# 2. 运行安装包(按提示 Enter 阅读协议、yes 同意、默认安装路径)wangxingjia@88dcb2233545:~$ bash 20235883_ai_practice/Miniconda3-latest-Linux-x86_64.sh
# 3. 安装完成后,重新加载 shell 配置,使 conda 命令生效wangxingjia@88dcb2233545:~$ source ~/.bashrc
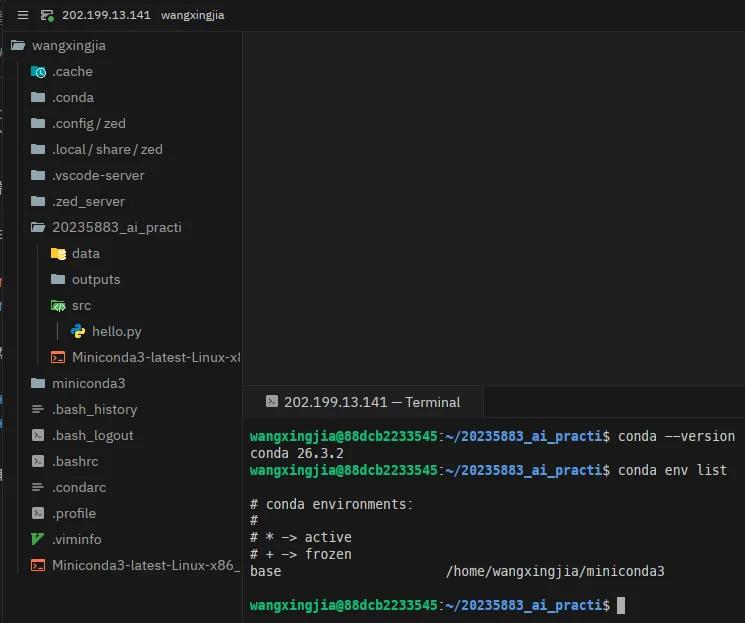
# 4. 检查 conda 是否安装成功wangxingjia@88dcb2233545:~/20235883_ai_practice$ conda --versionconda 26.3.2
# 5. 查看当前 Conda 环境列表wangxingjia@88dcb2233545:~/20235883_ai_practice$ conda env list# conda environments:## * -> active# + -> frozen#base /home/wangxingjia/miniconda3
# 6. 关闭自动激活 base 环境wangxingjia@88dcb2233545:~/20235883_ai_practice$ conda config --set auto_activate_base false终端截图:
(a) 为什么不建议直接把所有依赖安装到 base 环境中?
不建议把所有依赖都安装到 base 环境中,因为 base 是 Conda 的默认环境,所有项目共用会导致不同项目的依赖版本冲突,也不利于环境的复现和隔离。最佳实践是为每个项目单独创建一个虚拟环境,安装该项目所需的特定版本依赖。
(b) Miniconda 安装在 Ubuntu 服务器中,还是安装在本地个人电脑中?
安装在 Ubuntu 服务器中。 因为安装命令是在远程终端里执行的,安装路径 /home/wangxingjia/miniconda3 也位于远程 Ubuntu 服务器的文件系统上,本地个人电脑只是通过 Zed/VS Code Remote-SSH 远程操作。
(c) source ~/.bashrc 的作用是什么?
source ~/.bashrc 的作用是重新加载当前 shell 的配置文件。Miniconda 安装程序会在 ~/.bashrc 末尾写入 conda 的初始化脚本(包括把 conda 加入 PATH、注册 shell 函数等)。执行 source ~/.bashrc 后,这些修改会立即在当前终端生效,无需重新登录或新开终端,所以 conda --version 等命令才能被识别。
Problem (conda1): Understanding Conda and pip
(a) Conda 环境解决了什么问题?
Conda 环境主要解决了 Python 项目之间的依赖冲突和环境隔离 问题。不同项目可能依赖同一个库的不同版本,如果所有包都安装到同一个环境中,很容易造成版本不兼容、项目无法运行的情况。通过为每个项目创建独立的 Conda 环境,可以让各项目的依赖互不干扰,也便于环境的迁移和复现。
(b) pip install 安装的包一定属于整个 Ubuntu 系统吗?
不一定。 pip 安装包的位置取决于当前激活的是哪个 Python 解释器。激活某个 Conda 环境后,再使用 pip install 安装的包会被安装到该 Conda 环境对应的 site-packages 目录中(例如 /home/wangxingjia/miniconda3/envs/<env_name>/lib/pythonX.X/site-packages/),而不会影响整个 Ubuntu 系统的 Python 环境。
(c) 请解释 Ubuntu、Miniconda、Conda environment、pip 之间的层级关系
四者的层级关系可以概括为:Ubuntu 是操作系统层,提供底层的运行环境和系统级包管理工具 apt;Miniconda 是安装在 Ubuntu 上的一个 Python 发行版与环境管理工具,它自带 conda 和基础 Python;Conda environment 是 Miniconda 创建的多个相互隔离的 Python 运行环境,每个环境拥有独立的解释器和依赖;pip 则是在某个 Conda 环境(或系统 Python)内部安装、管理 Python 第三方库的工具。因此,层级关系是:Ubuntu 承载 Miniconda,Miniconda 管理多个 Conda environment,每个 environment 中可以使用 pip 安装独立的 Python 包。
Problem (env1): Building a Conda inference environment
创建并配置名为 ai_infer 的 Conda 环境,用于后续模型推理实验。
完整命令记录:
# 1. 创建 ai_infer 环境,指定 Python 3.10wangxingjia@88dcb2233545:~$ conda create -n ai_infer python=3.10
# 2. 激活环境wangxingjia@88dcb2233545:~$ conda activate ai_infer
# 3. 检查 Python 版本(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ python --versionPython 3.10.20
# 4. 检查 pip 版本(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ pip --versionpip 26.1.1 from /home/wangxingjia/miniconda3/envs/ai_infer/lib/python3.10/site-packages/pip (python 3.10)
# 5. 安装 numpy 和 torch(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ pip install numpy torch
# 6. 检查 numpy 和 torch 是否安装成功(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ python -c "import numpy; print(numpy.__version__)"2.2.6
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ python -c "import torch; print(torch.__version__)"# torch 成功导入并输出版本号
# 7. 确认当前 Python 来自 ai_infer 环境(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ which python/home/wangxingjia/miniconda3/envs/ai_infer/bin/python
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ which pip/home/wangxingjia/miniconda3/envs/ai_infer/bin/pip终端截图:
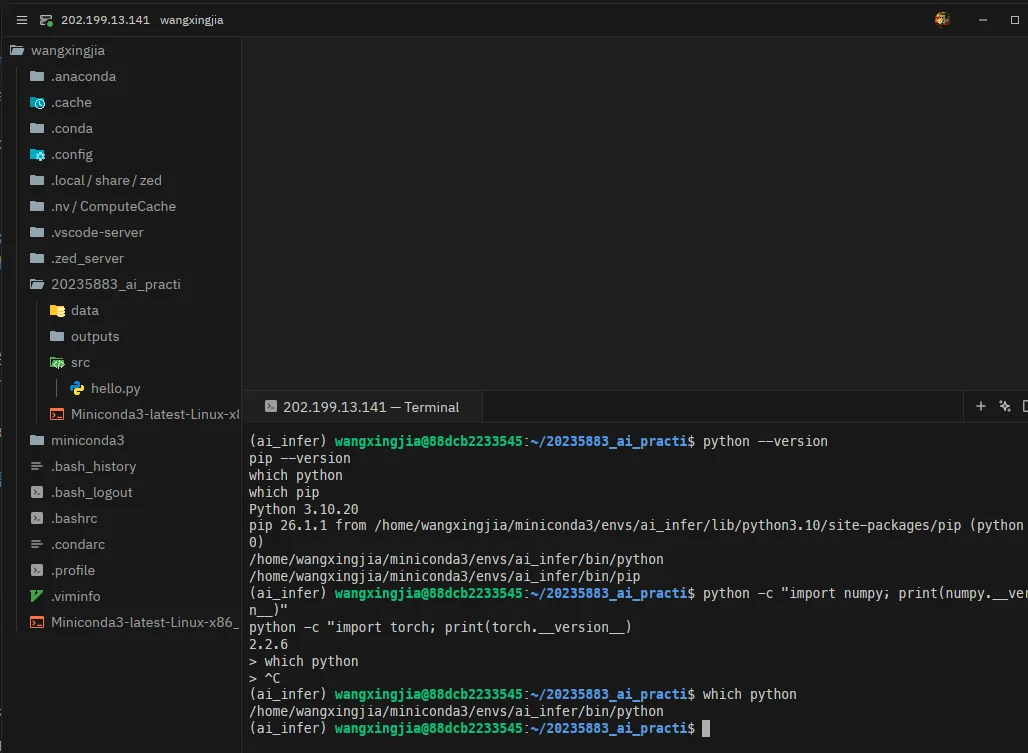
如何判断当前是否已经进入正确的 Conda 环境?
可以通过以下几点确认当前已进入 ai_infer 环境:
- 提示符前缀:终端命令行前出现
(ai_infer)标识,例如(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$。 which python路径:输出为/home/wangxingjia/miniconda3/envs/ai_infer/bin/python,而不是系统 Python 或base环境的路径。- Python 版本:
python --version输出Python 3.10.20,与创建环境时指定的版本一致。 pip --version路径:同样指向ai_infer环境目录下的pip,说明安装的包会进入该环境。
Problem (infer1): First model inference
(a) 运行 inference.py
src/inference.py 的代码如下:
import torchx = torch.tensor([[1.0, 2.0, 3.0]])w = torch.tensor([[0.2], [0.5], [0.3]])y = x @ wprint("Input:", x)print("Weight:", w)print("Output:", y)运行命令与输出:
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ cd src(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice/src$ python inference.pyInput: tensor([[1., 2., 3.]])Weight: tensor([[0.2000], [0.5000], [0.3000]])Output: tensor([[2.1000]])终端截图:
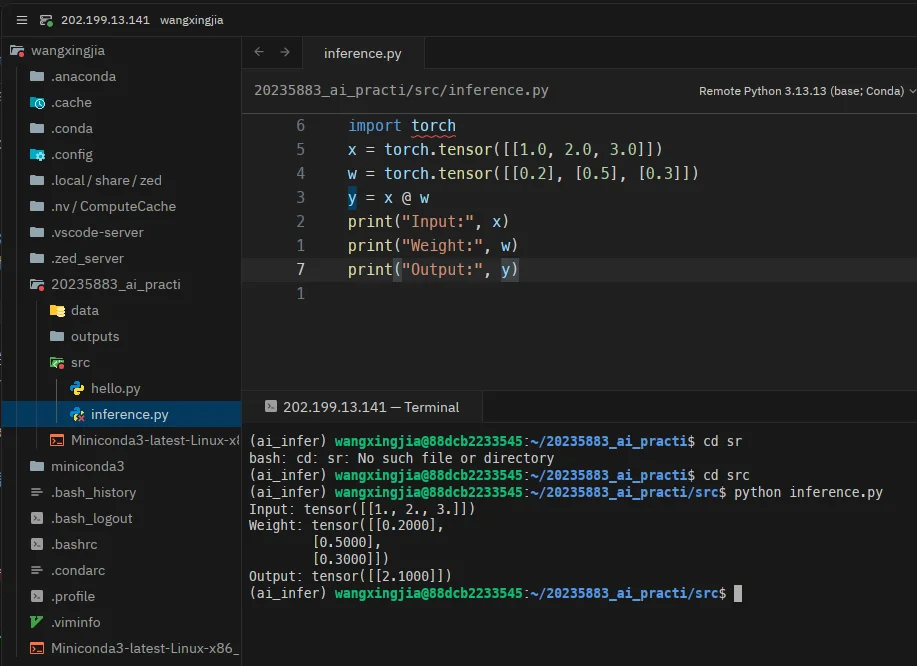
生成的 output.txt 内容:
Input: tensor([[1., 2., 3.]])Weight: tensor([[0.2000], [0.5000], [0.3000]])Output: tensor([[2.1000]])(b) 解释 x @ w 的含义
x @ w 是 PyTorch 中的矩阵乘法运算符,表示将输入张量 x 与权重张量 w 相乘。在这个简单推理示例中,它计算输入特征与对应权重的加权和:把每个输入元素乘以其权重后求和,得到模型的输出。这是神经网络中最基本的线性变换操作,模拟了一个没有激活函数的单层线性神经元。
(c) 修改输入并再次运行
将 inference.py 中的输入改为:
x = torch.tensor([[2.0, 1.0, 4.0]])再次运行:
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice/src$ python inference.pyInput: tensor([[2., 1., 4.]])Weight: tensor([[0.2000], [0.5000], [0.3000]])Output: tensor([[2.1000]])终端截图:
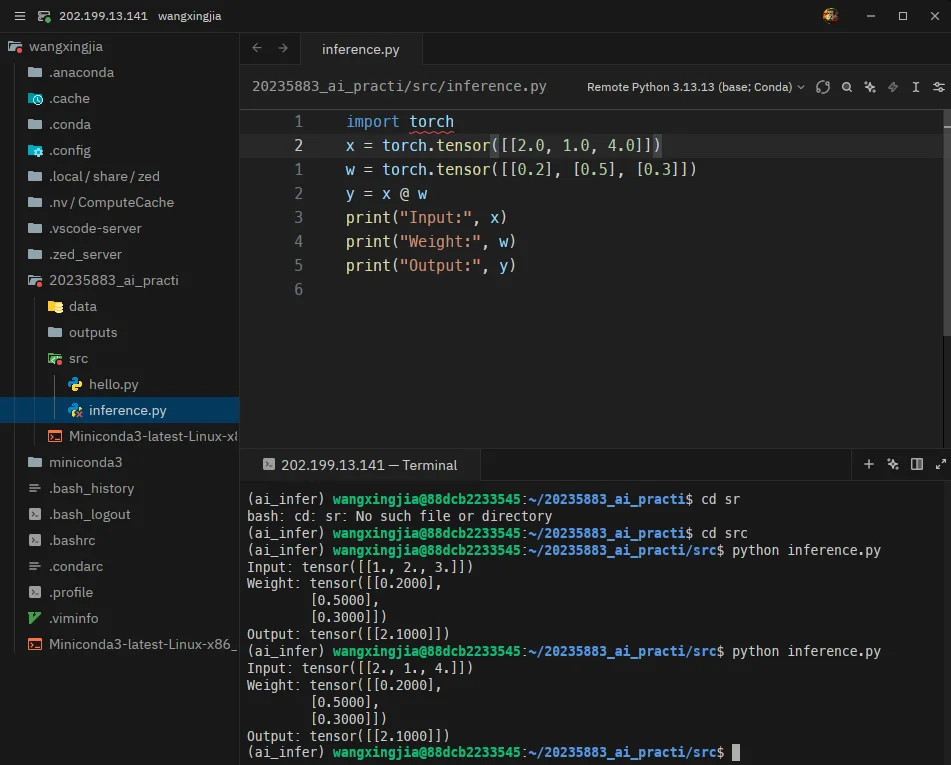
输出变化说明:
从数值上看,输出仍然是 tensor([[2.1000]]),没有发生变化。这是因为新的输入 [2.0, 1.0, 4.0] 与权重 [0.2, 0.5, 0.3] 的加权和为:
2.0 × 0.2 + 1.0 × 0.5 + 4.0 × 0.3 = 0.4 + 0.5 + 1.2 = 2.1恰好与原输入 [1.0, 2.0, 3.0] 的加权和:
1.0 × 0.2 + 2.0 × 0.5 + 3.0 × 0.3 = 0.2 + 1.0 + 0.9 = 2.1相等。因此,虽然输入数据变了,但权重保持不变,且新输入与权重的点积恰好相同,所以最终输出没有变化。这也说明模型输出由输入和权重共同决定,改变输入不一定总是改变输出。
Problem (advanced1): Optional profiling with Scalene
本题为可选进阶题,使用 Scalene 分析并优化一个简单的神经网络前向传播程序。
1. 在 ai_infer 环境中安装 Scalene
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ pip install scalene2. 编写并运行 src/slow_nn.py
import timeimport torch
def slow_forward(x, w1, b1, w2, b2): outputs = [] for i in range(x.shape[0]): h = torch.relu(x[i] @ w1 + b1) y = h @ w2 + b2 outputs.append(y) return torch.stack(outputs)
def main(): torch.manual_seed(0) batch_size = 4096 input_dim = 256 hidden_dim = 512 output_dim = 10 steps = 20
x = torch.randn(batch_size, input_dim) w1 = torch.randn(input_dim, hidden_dim) b1 = torch.randn(hidden_dim) w2 = torch.randn(hidden_dim, output_dim) b2 = torch.randn(output_dim)
start = time.perf_counter() for _ in range(steps): y = slow_forward(x, w1, b1, w2, b2) end = time.perf_counter()
print("Output shape:", y.shape) print("Elapsed seconds:", end - start)
if __name__ == "__main__": main()运行结果:
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ python src/slow_nn.pyOutput shape: torch.Size([4096, 10])Elapsed seconds: 48.699921720020943. 编写并运行优化后的 src/fast_nn.py
import timeimport torch
def fast_forward(x, w1, b1, w2, b2): h = torch.relu(x @ w1 + b1) y = h @ w2 + b2 return y
def main(): torch.manual_seed(0) batch_size = 4096 input_dim = 256 hidden_dim = 512 output_dim = 10 steps = 20
x = torch.randn(batch_size, input_dim) w1 = torch.randn(input_dim, hidden_dim) b1 = torch.randn(hidden_dim) w2 = torch.randn(hidden_dim, output_dim) b2 = torch.randn(output_dim)
start = time.perf_counter() for _ in range(steps): y = fast_forward(x, w1, b1, w2, b2) end = time.perf_counter()
print("Output shape:", y.shape) print("Elapsed seconds:", end - start)
if __name__ == "__main__": main()运行结果:
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ python src/fast_nn.pyOutput shape: torch.Size([4096, 10])Elapsed seconds: 2.3824319969866274. 使用 Scalene 分析
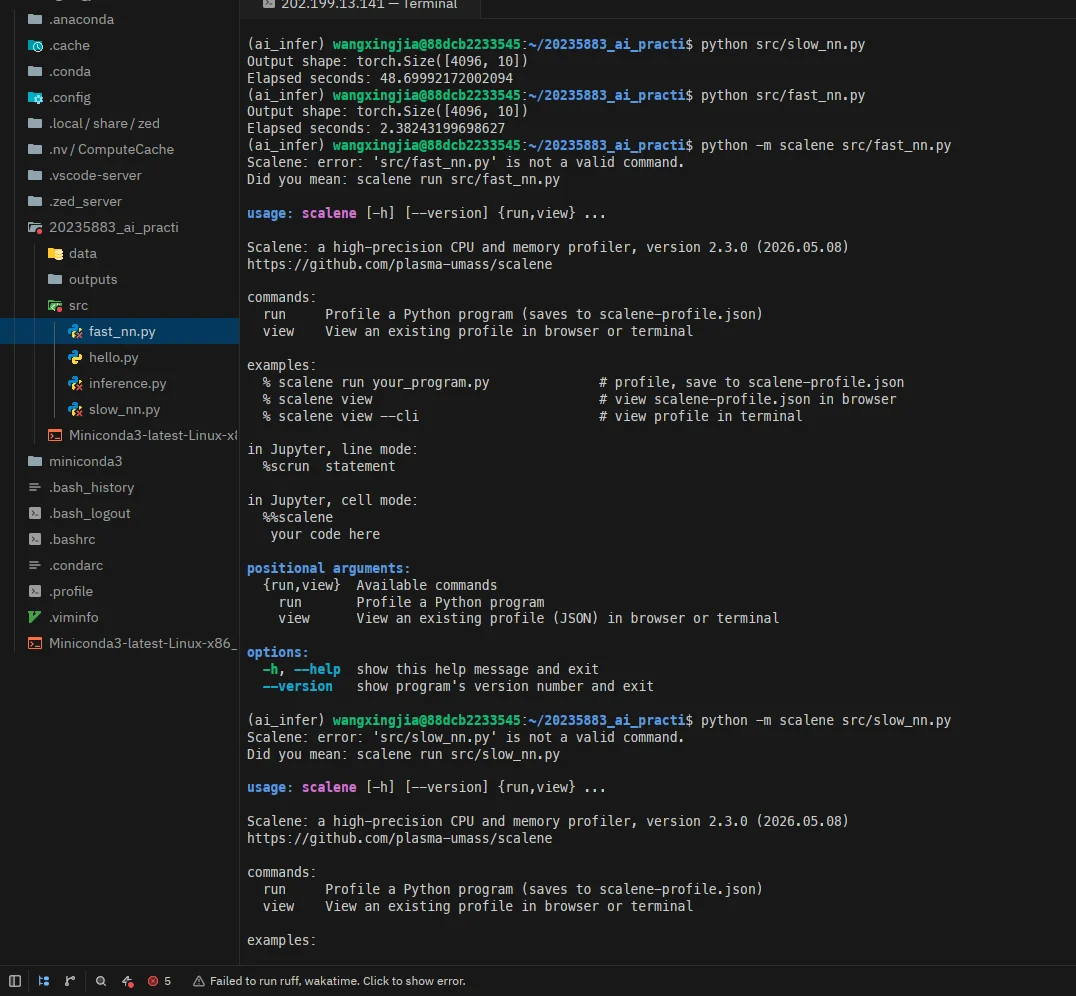
尝试使用 python -m scalene 运行 Scalene:
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ python -m scalene src/fast_nn.pyScalene: error: 'src/fast_nn.py' is not a valid command.Did you mean: scalene run src/fast_nn.py
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practice$ python -m scalene src/slow_nn.pyScalene: error: 'src/slow_nn.py' is not a valid command.Did you mean: scalene run src/slow_nn.pyScalene 2.3.0 需要通过子命令 scalene run <脚本> 来运行,而不是 python -m scalene <脚本>。正确用法如下:
scalene run src/slow_nn.pyscalene run src/fast_nn.py终端截图:
(a) slow_nn.py 的主要性能瓶颈在哪里?
slow_nn.py 的主要性能瓶颈在于 slow_forward 函数中的 Python 级 for 循环。程序逐条遍历 batch 中的 4096 个样本,每次只对一个样本做矩阵乘法,导致大量时间消耗在 Python 解释器循环调度、张量索引和小规模核函数启动开销上,无法充分利用 PyTorch 底层优化的批量矩阵运算能力。
(b) 采用了什么优化思路?
优化思路是把逐条样本的循环改为 batch 矩阵计算。在 fast_forward 中,直接用 x @ w1 对整个 batch 进行矩阵乘法,配合广播机制一次性完成 ReLU 和第二层线性变换。这样 PyTorch 可以调用高度优化的 BLAS/MKL 底层实现,充分利用 CPU 的 SIMD 和并行能力,减少 Python 层循环开销。
(c) 优化前后是否有明显提升?
有明显提升。 slow_nn.py 运行 20 步共耗时约 48.70 秒,而 fast_nn.py 仅耗时约 2.38 秒,速度提升了约 20 倍。两者输出形状完全一致(torch.Size([4096, 10])),说明计算结果等价,但 batch 化矩阵运算显著减少了运行时间。Scalene 若按正确命令运行,预计会显示 slow_nn.py 的 Python 循环部分占用绝大部分 CPU 时间,而 fast_nn.py 的时间主要集中在 PyTorch 的底层 C++ 矩阵乘法核上,Python 解释器开销大幅减少。
Problem (export1): Exporting the environment
将配置好的 ai_infer 环境导出为 environment.yml,便于后续复现和共享。
完整命令记录:
(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practi$ conda env export > environment.yml(ai_infer) wangxingjia@88dcb2233545:~/20235883_ai_practi$ cat environment.yml导出的 environment.yml 内容如下:
name: ai_inferchannels: - defaultsdependencies: - _libgcc_mutex=0.1=main - _openmp_mutex=5.1=52_gnu - bzip2=1.0.8=h5eee18b_6 - ca-certificates=2026.5.14=h06a4308_0 - ld_impl_linux-64=2.44=h9e0c5a2_3 - libexpat=2.8.1=h7354ed3_1 - libffi=3.4.8=h06d3fd0_3 - libgcc=15.2.0=h69a1729_8 - libgcc-ng=15.2.0=h166f726_8 - libnsl=2.0.0=h5eee18b_0 - libstdcxx=15.2.0=h39759b7_8 - libuuid=1.41.5=h5eee18b_0 - libxcb=1.17.0=h9b100fa_0 - libzlib=1.3.2=h47b2149_0 - ncurses=6.5=h7934f7d_0 - openssl=3.5.7=h1b28b03_0 - packaging=26.0=py310h06a4308_0 - pip=26.1.1=pyhc872135_1 - pthread-stubs=0.3=h0ce48e5_1 - python=3.10.20=h17756b0_1 - readline=8.3=hc2a1206_0 - sqlite=3.53.2=h795bf6d_0 - tk=8.6.15=h54e0aa7_0 - tzdata=2026b=he532380_0 - wheel=0.47.0=py310h06a4308_0 - xorg-libx11=1.8.12=h9b100fa_1 - xorg-libxau=1.0.12=h9b100fa_0 - xorg-libxdmcp=1.1.5=h9b100fa_0 - xorg-xorgproto=2024.1=h5eee18b_1 - xz=5.8.2=h448239c_0 - zlib=1.3.2=h47b2149_0 - pip: - annotated-doc==0.0.4 - annotated-types==0.7.0 - anyio==4.14.0 - certifi==2026.6.17 - click==8.4.1 - cloudpickle==3.1.2 - cuda-bindings==13.3.1 - cuda-pathfinder==1.5.5 - cuda-toolkit==13.0.2 - exceptiongroup==1.3.1 - filelock==3.29.4 - fsspec==2026.6.0 - h11==0.16.0 - hf-xet==1.5.1 - httpcore==1.0.9 - httpx==0.28.1 - huggingface-hub==1.20.1 - idna==3.18 - jinja2==3.1.6 - markdown-it-py==4.2.0 - markupsafe==3.0.3 - mdurl==0.1.2 - mpmath==1.3.0 - networkx==3.4.2 - numpy==2.2.6 - nvidia-cublas==13.1.1.3 - nvidia-cuda-cupti==13.0.85 - nvidia-cuda-nvrtc==13.0.88 - nvidia-cuda-runtime==13.0.96 - nvidia-cudnn-cu13==9.20.0.48 - nvidia-cufft==12.0.0.61 - nvidia-cufile==1.15.1.6 - nvidia-curand==10.4.0.35 - nvidia-cusolver==12.0.4.66 - nvidia-cusparse==12.6.3.3 - nvidia-cusparselt-cu13==0.8.1 - nvidia-ml-py==13.610.43 - nvidia-nccl-cu13==2.29.7 - nvidia-nvjitlink==13.0.88 - nvidia-nvshmem-cu13==3.4.5 - nvidia-nvtx==13.0.85 - psutil==7.2.2 - pydantic==2.13.4 - pydantic-core==2.46.4 - pygments==2.20.0 - pyyaml==6.0.3 - regex==2026.5.9 - rich==15.0.0 - safetensors==0.8.0 - scalene==2.3.0 - setuptools==81.0.0 - shellingham==1.5.4 - sympy==1.14.0 - tokenizers==0.22.2 - torch==2.12.1 - tqdm==4.68.3 - transformers==5.12.1 - triton==3.7.1 - typer==0.25.1 - typing-extensions==4.15.0 - typing-inspection==0.4.2prefix: /home/wangxingjia/miniconda3/envs/ai_infer文件中记录了哪些信息?
environment.yml 主要记录了以下几类信息:
name:环境名称ai_infer。channels:Conda 包来源渠道,这里使用defaults。dependencies:通过 Conda 安装的依赖包及其精确版本和构建号,例如python=3.10.20、pip=26.1.1。pip:子项:通过 pip 安装的 Python 库及其版本,例如numpy==2.2.6、torch==2.12.1、scalene==2.3.0、transformers==5.12.1。prefix:环境在文件系统中的绝对路径/home/wangxingjia/miniconda3/envs/ai_infer。
为什么 AI 项目需要保存环境配置?
AI 项目通常依赖大量第三方库,且这些库对版本非常敏感(例如 PyTorch、CUDA、transformers 之间需要严格匹配)。保存 environment.yml 可以精确记录项目运行所需的所有依赖及其版本,便于在另一台机器或 teammate 的环境中通过 conda env create -f environment.yml 一键复现相同环境,避免“在我电脑上能跑”的问题,也方便项目迁移、部署和长期维护。
Problem (debug1): Debugging a missing package
遇到 ModuleNotFoundError: No module named 'torch' 怎么办?
这个错误表示当前 Python 解释器在搜索路径中找不到名为 torch 的模块。常见原因包括:没有安装 PyTorch、安装在了错误的 Conda/虚拟环境中、当前未激活正确的环境,或者使用了系统 Python 而非项目环境内的 Python。排查时应先确认自己是否在正确的环境中,可以依次执行 which python、python --version 和 conda env list 查看当前 Python 路径、版本和可用环境;然后执行 pip list | grep torch 或 python -c "import torch" 确认 torch 是否已安装。如果当前环境不对,应使用 conda activate ai_infer 切换到项目环境;如果 torch 未安装,则在该环境中执行 pip install torch 进行安装;若版本冲突,可尝试指定兼容版本,或根据 environment.yml 重新创建环境。养成在进入项目前激活对应环境的习惯,是避免此类问题的最佳做法。
总结
Day1 从零起步完成了从远程连接到模型推理的全流程搭建,核心收获如下:
- 远程开发:通过 Remote-SSH 连接服务器,实现“本地写代码、远程跑任务“
- Linux 命令行基础:掌握了
cd、mkdir、cp、mv、rm等文件操作,以及apt、tree等工具的使用。 - 环境管理:用 Miniconda + Conda 虚拟环境隔离项目依赖,基本告别“在我电脑上能跑“的问题。
- 推理实战:用 PyTorch 写了一个单层线性变换
x @ w,并对比了逐条循环与 batch 矩阵计算的性能差距。
其实大部分都会,除了PyTorch,还得捡起来线性代数的知识才行
人工智能实训Day1:Ubuntu 基础与 Conda 推理环境搭建
作者:xingwangzhe
本文链接:https://xingwangzhe.fun/posts/ai-training-ubuntu-conda-day1/
本文采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。
留言评论